|
|
 |
|
PROGRAM PROPOSAL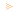 SCIENTIFIC PROGRAM SCIENTIFIC PROGRAM

Das in diesem Antrag formulierte Forschungsprogramm "Organic Computing" spricht einen breiten,
hochaktuellen Themenbereich an, dessen Fragestellungen teilweise bereits vor vielen Jahren formuliert
wurden. Rechensysteme lebensähnlich zu gestalten, gehört seit langem zu den Fernzielen der
technischen Entwicklung. Die aktuelle Dringlichkeit der Bearbeitung dieser Themen ergibt sich durch
das absehbare Szenario, von einer Vielzahl intelligenter Systeme umgeben zu sein, deren Komplexität
nur beherrschbar sein wird, wenn neue, mehr am Menschen ausgerichtete Nutzungs- und Kooperationsmuster
verfügbar sind.
Im Folgenden wird zunächst der für dieses Schwerpunktprogramm relevante Stand der Technik
dargelegt, darauf folgt eine Präzisierung der Ziele, die durch das Programm erreicht werden sollen,
und es wird das geplante Arbeitsprogramm erläutert.
1.1 Stand der Forschung
Der hier verwendete Begriff des "Organic Computing" entstand während eines Workshops über Zukunftsthemen
der Technischen Informatik, der im November 2002 die Ergebnisse mehrerer Workshops
von Fachgruppen des GI-Fachbereichs "Technische Informatik und Architekturen von Rechensystemen"
zusammenfasste, die im Jahr 2002 durchgeführt worden waren mit dem Ziel, die technologischen
Entwicklungen der nächsten 5-10 Jahre abzuschätzen und die daraus für die Informatik
entstehenden wissenschaftlichen Herausforderungen bezüglich der Gestaltung zukünftiger Informations-
und Kommunikationssysteme abzuleiten. Die Ergebnisse des Workshops wurden in einem
Positionspapier der GI und der ITG zusammengefasst [1], das von ca. 20 Vertretern der Technischen
Informatik aus Hochschule und Industrie getragen wird.
Unabhängig von dieser Aktivität gibt es die durch Christoph von der Malsburg geprägte Initiative zum
Organic Computing [2].
Bereits im November 2001 fand der erste von ihm organisierte Workshop zum
Organic Computing statt. Anders als die hier beschriebene Initiative versteht von der Malsburg Organic
Computing als eine Kombination von Neurowissenschaften, Molekularbiologie und Software. Im
Mittelpunkt des Interesses steht die Entwicklung neuartiger rechnender Systeme unter Ausnutzung
biologischer Prinzipien. Dies hat eine Realisierungsperspektive von mindestens 10 bis 15 Jahren und
geht deshalb in den Zielvorstellungen deutlich über die zeitlichen Perspektiven des geplanten
Schwerpunktprogramms hinaus, bei dem die in 5 bis 8 Jahren verfügbaren technologischen Komponenten
die Basis für den Systementwurf darstellen sollen.
Forrester Research hat im April 2002 eine Studie vorgelegt, in der Organic IT als neue Strategie für
Informationssysteminfrastrukturen propagiert wird [3]. Diese Strategie ist von großen IT-Firmen wie
HP, IBM und Microsoft aufgegriffen worden und hat bereits zum Angebot neuer adaptiver Serverarchitekturen
geführt.
Eng verwandt mir dem hier vorgelegten Programm ist auch das von IBM propagierte Autonomic
Computing [4,
5]. Inspiriert durch
die Funktionalität des vegetativen Nervensystems wird ein Management
von Rechensystemen vorgeschlagen, dass auf Veränderungen der Umwelt des Systems selbständig
reagiert, um die gewünschte Funktionalität des Systems aufrecht zu erhalten. Dies erfordert
einen gewissen Grad der Selbstorganisation, so dass beispielsweise auf Störungen "selbstheilend"
reagiert werden kann. In [6]
werden insbesondere eine Reihe von "selbst-x" Eigenschaften autonomer
Systeme postuliert: Im Vordergrund steht das Selbstmanagement der Systeme, dies bedingt Eigenschaften
der Selbstkonfiguration, der Selbstoptimierung, der Selbstheilung, des Selbstschutzes. Diese
Eigenschaften werden als unausweichliche Forderung angesehen, ohne die zukünftige komplexe
Systeme nicht mehr zu managen bzw. nicht mehr beherrschbar sein werden.
Die Idee, zukünftigen Rechensystemen diese Selbst-x Eigenschaften zu geben, findet man mittlerweile
in einer Reihe von Forschungsprogrammen zur Untersuchung und Entwicklung komplexer Systeme
(unter anderem auch im Future und Emergent Technologies-Programm der EU [7] und im australischen
CSIRO Center for Complex Systems [8].
Das Prinzip der Selbstorganisation ist bereits seit einer Reihe von Jahren Gegenstand der Forschung.
Im Jahr 1989 veröffentlichte G. Jetschke ein Buch über die "Mathematik der Selbstorganisation" [9], in
dem er die Konvergenz einfacher Systeme zu statischen Formen behandelt. R. Whitaker gibt 1995
einen Überblick über Untersuchungen zur Selbstorganisation [10] und konzentriert sich dabei auf den
Begriff und die Theorie der Autopoiese, die von Maturana und Varela [11] ca. 1980 entwickelt wurde.
Mit dem Begriff Autopoiese werden Systeme charakterisiert, die ihre Organisation auch über eine
Folge von Änderungen ihrer Umgebung aufrechterhalten und ihre Komponenten selbsttätig reproduzieren.
Überlegungen zur Charakterisierung selbstorganisierender Systeme findet man auch bei F. Heylighen
[12], dessen
wissenschaftliches Hauptinteresse der Evolution von Komplexität [13] gilt, auch er sieht
große Probleme in der Beherrschbarkeit der sich derzeit entwickelnden Informatik-Systeme und sieht
durch Selbstorganisation einen möglichen Ausweg [14]. Wie auch einige andere Autoren führt er als
Beispiele für Selbstorganisation das beobachtbare Verhalten biologischer Systeme an, insbesondere
von Staaten bildenden Insekten. Als elementares Beispiel für die Realisierung von Selbstorganisation
nennt er zu Recht auch das Internet: Dessen Kommunikationsstrukturen bzw. Kommunikationsprotokolle
wurden gezielt so gewählt, dass auch bei Störungen der Netzwerkstruktur Kommunikation weiterhin
möglich ist. Zur Unterstützung von Arbeiten im Bereich der Selbstorganisation sind auch Simulationswerkzeuge,
u.a. das System "Starlogo" (Mitch Resnick, MIT [15]) entstanden, das eine einfach
zu bedienende Umgebung zur Erzeugung und Untersuchung selbstorganisierender Systeme darstellt.
Ein weiterer wichtiger Aspekt der Selbstorganisation ist die Beobachtung, dass sich aus dem (lokalen)
Handeln der Individuen eines sich selbst organisierenden Systems ein (global) beobachtbares, sogenanntes
emergentes Verhalten ergeben kann. Von Emergenz redet man immer dann, wenn ein System
die folgenden Eigenschaften hat (gemäß der Definition in der Zeitschrift "Emergence"
[16]):
- Das globale Verhalten ist von anderer Art als das der einzelnen Komponenten (insbesondere keine lineare Kombination der Einzelhandlungen).
- Die Entfernung einzelner Komponenten führt nicht zu einem Ausfall des gesamten Systems.
- Das globale Verhalten ist völlig neuartig im Vergleich mit den vorhandenen Komponenten, d.h. das emergente Verhalten scheint unvorhersehbar und nicht ableitbar von den einzelnen Komponenten des Systems zu sein, und es kann auch nicht auf diese reduziert werden.
Zum Phänomen der Emergenz gibt es eine Reihe von Arbeiten, seit ein paar Jahren sogar die eben
zitierte spezielle Zeitschrift. Erwähnt sei insbesondere die Monographie von Stephen Jones [17] und
der Aufsatz von D. Hillis [18].
In vielen dieser Arbeiten werden beobachtbare Phänomene in biologischen
Systemen untersucht und auf künstliche Systeme übertragen. Dies hat bereits zu einer Reihe
interessanter und auch erfolgreich angewandter Ansätze in der Informatik geführt, wie beispielsweise
zu Evolutionären Algorithmen [19]
und zu Ameisenalgorithmen sowie - etwas allgemeiner - zur Nutzung
von "Schwarmintelligenz" [20],
unter anderem zur Entwicklung neuer Routing-Strategien im
Internet und anderen Kommunikationssystemen [21] .
In diesem Bereich liegt auch ein wesentlicher
Teil der Arbeiten des Antragstellers H. Schmeck (u.A. [22, 23, 24, 25), der in seiner Arbeitsgruppe die
Wirkungsweise von Evolutionären Algorithmen und von Ameisenalgorithmen untersucht und in letzter
Zeit vor allem zur Bearbeitung dynamisch [26] (auch
stochastisch [27]) veränderlicher und multikriterieller
[28] Optimierungsprobleme einsetzt. Ein wichtiger Aspekt seiner Arbeiten ist auch die parallele
[29, 30, 31] und verteilte [32, 33] Implementierung dieser naturanalogen Optimierungsverfahren.
Durch die Bearbeitung eines Teilprojekts innerhalb des vom BMB+F geförderten Verbundprojekts
SESAM [34]
beschäftigt sich die Arbeitsgruppe ebenfalls mit dem Thema der Selbstorganisation, hier
bezogen auf die Schaffung selbstorganisierter Märkte mit spontanem Eintritt der Marktteilnehmer,
realisiert über Peer-to-Peer Systeme.
Das geplante Schwerpunktprogramm zum Organic Computing hat als einen äußerst wichtigen Bereich
die Entwicklung geeigneter Prinzipien für die technologische Basis einer zukünftig beherrschbaren
und anpassungsfähigen (insbesondere "menschenfreundlichen" Gestaltung der uns umgebenden
Informationsverarbeitungsinfrastruktur. In den letzten Jahren haben sich die Systeme der Informationsverarbeitung
in mehrerer Hinsicht bereits dramatisch gewandelt. Partiell beruht dies auf der üblicherweise
als "Moore's Law" bezeichneten Entwicklung, dass mikro- (und nano-)elektronische Schaltungen
eine jährliche Kapazitätssteigerungsrate von ca. 66% aufweisen. Das entspricht einer Verdopplung
der Anzahl Transistoren pro Chip alle 18 Monate und ebenso einer Verdopplung der Anzahl
Instruktionen pro Sekunde. Dieser Trend wird sich gemäß der neuesten Technologie-Roadmap [35,
36] auch in den nächsten
Jahren fortsetzen und nach bisheriger Einschätzung erst nach 2010 abflachen.
Die heutige 90nm-Technologie ermöglicht bereits mehrere 100 Millionen Transistoren pro Chip.
Bis 2012 wird sich diese Zahl - konservativ betrachtet - verzehnfacht haben, ein Chip wird bis dahin
also mehrere Milliarden Transistoren enthalten. Zum Vergleich: ein Pentium I-Prozessor von Intel aus
dem Jahre 1992 hatte eine Komplexität von ca. 3 Millionen Transistoräquivalenten.
Gleichzeitig wächst die Bandbreite der Kommunikationsinfrastrukturen, in Deutschland liefert das
Gigabit-Wissenschaftsnetz ein Backbone mit 10Gbps und selbst im Nahbereich ist mit Ultra Wide
Band eine Übertragungstechnologie im Gbps-Bereich zu erwarten.
Aus diesem enormen Kapazitätswachstum resultieren einerseits Möglichkeiten zur Schaffung immer
leistungsfähigerer Serverarchitekturen, andererseits erhöht sich auch die (potentielle) Leistungsfähigkeit
eingebetteter Systeme drastisch. In beiden Richtungen wächst die Komplexität der realisierten
Systeme nicht nur durch die erhöhte Leistungsfähigkeit einzelner Komponenten sondern in noch
höherem Maße durch die immer stärkere und auch wesentlich einfachere Vernetzung. Insbesondere
die ad-hoc Vernetzung mobiler und eingebetteter Systeme wird zukünftig eine wichtige Rolle bei der
Realisierung selbstorganisierende Systeme spielen.
Ein wichtiger aktueller Trend ist die Integration von funktional immer komplexeren, digital-analog
hybriden Systemen auf einem einzigen Chip (SoC - System on Chip). Systeme, welche noch vor
wenigen Jahren aus mehreren Einzelkomponenten auf mehreren Leiterplatten aufgebaut waren,
können heute als IP (Intellectual Property) - Blöcke auf einem einzigen Chip implementiert werden. Die
Gartner-Gruppe prognostiziert, dass bis zum Jahr 2006 zwei Drittel aller ASICs nach der SoCMethode
entworfen werden, und das Umsatzvolumen des SoC-Geschäfts sich auf ca. 50 Milliarden
US Dollar jährlich belaufen wird.
Mit diesen verfügbaren Chipkapazitäten haben sich aber auch die Schlüsselherausforderungen beim
integrierten Systementwurf verschoben. Das Hauptziel wird zukünftig nicht mehr heißen "Wie bringe
ich noch mehr Transistoren auf ein Chip?" sondern "Wie entwickle ich ein System derartiger Komplexität
mit vertretbaren Kosten und innerhalb nützlicher Frist (Time to market)?" Das über Jahrzehnte
bestehende Kapazitätsproblem hat sich somit in ein Komplexitätsproblem gewandelt. Bei den Kosten
dominieren nicht die mit zunehmender Integrationsdichte ebenfalls stark steigenden Masken- und
Herstellungskosten, sondern die Entwicklungs- und Testkosten immer größer werdender Entwicklerteams.
Chip-Validierung und -Test bestimmen immer nachhaltiger die Entwicklungszeiten und Kosten
integrierter Systeme.
Erforderlich sind deshalb vor allem auch neue Konzepte für SoC-Architekturen, die sowohl Mikroprozessoren
als auch rekonfigurierbare Hardwarekomponenten enthalten werden (siehe z.B. [37]). In
diesem Bereich betätigt sich schwerpunktmäßig der Antragsteller Theo Ungerer, der vor allem wichtige
Beitrage zur Entwicklung mehrfädiger Prozessorarchitekturen [38] geliefert hat.
Vorarbeiten von Theo Ungerer im Bereich des mehrfädigen Prozessorentwurfs geschahen mit dem
Entwurf des mehrfädigen Rhamma-Prozessors [39]
1993-1996, eines mehrfädig superskalaren Prozessors
[40] 1995-96,
eines SMT-Multimedia-Prozessors [41] 1997-2000 und des Komodo-
Mikrocontrollers [42] 1999-2004.
Im Komodo-Projekt wurde ein mehrfädiger Java-Mikrocontroller mit
dem Echtzeit-Scheduling-Algorithmen in Hardware implementiert und bewertet.
Mit der mehrfädigen Prozessortechnik, die eine überlappt parallele Ausführung von Befehlen mehrerer
Threads in einer Prozessor-Pipeline ermöglicht, und in Hardware integrierter Schedulingstrategien
lassen sich völlig neue Prozessor-Eigenschaften und Programmierschemata entwickeln. Die im Komodo-
Projekt neu entwickelte Guaranteed Percentage Scheduling-Technik [43] garantiert die weitgehende
zeitliche Isolation bzw. Entkopplung der Hardware-Threads untereinander. Sie bietet die
Grundlage dafür, dass Helper Threads mit einem festen Prozentsatz der Rechenleistung gleichzeitig
zu den Anwendungen ablaufen können. Damit kann auf mehrfädigen Prozessoren und Mikrocontrollern
neben der Anwendung ein Parallelsystem von Organic Managern (Observer) geschaffen werden,
die eine Überwachung der Anwendung und, falls von den Self-X-Eigenschaften gefordert, deren
Rekonfiguration durchführen können. Die Organic Manager bieten durch ihre Vernetzung und ihre
Kenntnisse des Zustandes der lokalen Applikationen die Basis für selbstorganisierende Algorithmen.
Eine wichtige Voraussetzung für die Möglichkeit der Anpassung technischer Komponenten an Veränderungen
im Einsatzumfeld ist die Verfügbarkeit rekonfigurierbarer Rechensysteme. In diesem Bereich
gibt es bereits seit Jahren mehrere erfolgreiche Tagungsreihen (wie beispielsweise die Reconfigurable
Architecture Workshops (RAW), die Field Programmable Logic Conference (FPL) oder die
International Conference on FPGAs (FPGA). Seit Juni 2003 werden wesentliche deutsche Forschungsaktivitäten
über Rekonfigurierbare Rechensysteme im gleichnamigen Schwerpunktprogramm
der DFG zusammengefasst [44],
auch der Antragsteller H. Schmeck ist hier mit einem Teilprojekt
beteiligt.
Neben rekonfigurierbaren Rechensystemen gibt es weitere Techniken, die eine dynamische Anpassung
technischer Systeme im Hinblick auf Selbstkonfiguration und Selbstoptimierung ermöglichen wie
-
Dynamic Voltage und Frequency Scaling (DVFS), um Prozessortakt und -spannung belastungsabhängig
zu regeln und dabei insbesondere den Energieverbrauch zu senken. Diese Technik wird
beispielsweise im Mikroprozessor Crusoe [45] der Transmeta Corporation angewandt. Auf Basis
des mehrfädigen Komodo-Mikrocontrollers wurden an der Universität Augsburg hardware-basierte
Verfahren des Energiemanagements entwickelt, welche die Arbeitsfrequenz und die Versorgungsspannung
(DVFS) des Prozessors verwalten [46] . Das Energiemanagement nutzt das Wissen
über die momentane Gesamt-Auslastung des Prozessors auf der Grundlage von mehrfädigen
Schedulingtechniken und passt die Arbeitsfrequenz (und die Versorgungsspannung) des Prozessors
dynamisch an die augenblicklichen Anforderungen an.
- Built-in Selftest Konzepte validieren Schaltungsteile bei Systemstart und teilweise auch im laufenden Betrieb (siehe z.B. [47])
-
Mechanismen und Strategien zur Unterstützung fehlertoleranten Verhaltens in komplexen Systemen.
Hier gibt es eine Fülle von Ergebnissen langjähriger Forschung, die allerdings erst in jüngster
Zeit durch das steigende Bewusstsein für die Notwendigkeit der Schaffung sicherer Systeme
wieder stärkere Aufmerksamkeit erfahren, so war ein wesentlicher Teil der letzten GI Jahrestagung
diesem Thema gewidmet [48].
Eine weitere wichtige Basis für die Entwicklung organischer Rechensysteme ist die Entstehung des
ubiquitären Rechnens, dessen Prinzip bereits 1991 von Mark Weiser entwickelt wurde [49]. 98% aller
Mikroprozessoren werden bereits heute in Gegenstände unserer Umgebung eingebettet. Sie sind
nicht als Computer im Sinne eines PC zu erkennen. Die Herausforderung besteht darin, diese zunehmend
vernetzte eingebettete Prozessorleistung sinnvoll zu organisieren und nutzbar zu machen. Auch
hier werden zukünftig Selbstorganisation und Adaptivität eine zentrale Rolle spielen. Ubiquitous und
Pervasive Computing haben sich mittlerweile zu einem stark beachteten Teilbereich der Informatikforschung
entwickelt. So gibt es im Jahr 2004 bereits die sechste Tagung "Ubiquitous Computing -
UbiComp 2004" [50].
Im Rahmen eines laufenden Forschungsprojekts von Prof. Ungerer an der Universität Augsburg wird
eine ubiquitäre Middleware entwickelt werden, welche die Anforderungen des Organic Computing
erfüllen soll. Die Middleware [51] basiert auf einem JXTA Peer-to-peer-Netz und sieht auf die Knoten
verteilte Organic Manager (Observer) vor, welche die Nachrichten überwachen und daraus Schlüsse
über zu optimierende Dienste (z.B. Dienstverschiebung bei Überlastung), über den Ausfall von Diensten
(Software-Watchdog-Funktion, Restart des ausgefallenen Dienstes auf dem gleichen oder einem
anderen Prozessor), über neu zu konfigurierende Dienste und über unautorisierte Zugriffe auf Dienste
ziehen. Ein Organic Manager kann über eine Software-Rekonfiguration Dienste einfügen, ersetzen
und verschieben. Damit soll ein Schritt in Richtung auf die Forderungen des Organic Computing erzielt
werden.
In einem weiteren Forschungsprojekt wird der Einsatz von Mechanismen für Kontextvorhersagen in
ubiquitären Systemen erforscht werden. Die dafür neu entwickelte Methode der Zustandsprädiktoren
[52, 53] geht auf die
Sprungvorhersagealgorithmen in Mikroprozessoren zurück. Ziel ist es, ein lernfähiges
System zu entwickeln, welches sich Fehlschätzungen merkt und seine Trefferwahrscheinlichkeit
erhöhen kann.
Organic Computing baut auf dem Zusammenspiel einer großen Anzahl von Einzel-Elementen auf.
Dabei wird von den Elementen erwartet, dass sie sich nicht starr an einprogrammierte Vorgaben
halten, sondern adaptiv auf Anforderungen von außen reagieren. Das Gesamt-Systemverhalten ergibt
sich dann wieder aus dem Zusammenspiel der Elemente (Emergenz). Von zentraler Bedeutung für
den technischen Einsatz der Prinzipien des Organic Computing wird daher ein tieferes Verständnis
organischer Systemarchitekturen sein. Es geht dabei sowohl um ein Verständnis natürlicher emergenter
Systeme wie auch um die Frage der Beherrschbarkeit von Selbstorganisation und Emergenz in
technischen Systemen. Dabei spielen vor allem die Anforderungen sicherheitskritischer Systeme wie
in der Automobiltechnik oder der Telekommunikation eine wichtige Rolle. Am SRA, dem Institut des
Mitantragstellers Christian Müller-Schloer, wird seit Jahren an unterschiedlichen Teilaspekten organischer
Systemarchitekturen gearbeitet.
Bei der technischen Nutzung von Artificial Life (AL)-Methoden sind dem Umfang und der Komplexität
der AL-Systeme oftmals durch die verfügbare Rechenleistung enge Grenzen gesetzt. Daher wurden
am SRA Untersuchungen zur Parallelisierbarkeit der einzelnen Rechenprozesse betrieben. Das
Ergebnis dieser Arbeiten war die Simulationsumgebung PARALLIFE [54]. Hier bewegen sich "Autonome
Agenten" ("Animats") in einer einfachen "Welt" wobei sowohl die Berechnungen zur Simulation
dieser "Welt" wie auch diejenigen für die Entscheidungsfindung der einzelnen Animats ("Gehirne") auf
mehrere Prozessoren verteilt wurden. Als Entscheidungsmodell fanden Neuronale Netze und Classifier
Systeme Anwendung.
Die hier gewonnenen Erkenntnisse wurden anhand der adaptiven Steuerung eines Air-Hockey-Spiels
auf Basis eines Fuzzy-Classifier-Systems weiterentwickelt [55]. Im Projekt SALSA wird am Beispiel
des Air-Hockey-Spiels die Lernfähigkeit simulierter Spieler in Reaktion auf unterschiedliche Schlägerformen
untersucht. Classifier-Systeme erlauben die Vor-Formulierung eines Basis-Regelsatzes (APriori-
Regeln) zur Erhöhung der Lerngeschwindigkeit sowie die Interpretation der gelernten Regeln
durch den Menschen. Das System besteht aus einem (zunächst simulierten) Mikrocontroller, auf dem
ein lernender Algorithmus läuft. Die Regelbasis wird durch Belohnungs- und Bestrafungsmechanismen
beeinflusst und mittels eines genetischen Algorithmus um neue Regeln ergänzt. Ebenfalls enthalten
ist eine Komponente zur Überwachung von Randbedingungen, mittels derer Aktionen vor der
Ausführung abgefangen werden, die das System in einen unsicheren oder unsinnigen Zustand versetzen
würden (Guarding). Im Rahmen dieses Vorhabens soll unter anderem geklärt werden, ob
unscharf (fuzzy) formulierte Regeln den Lernprozess [56] positiv beeinflussen.
Lokalität spielt bei der Beherrschung der Komplexität eine wesentliche Rolle, da sie zentrale Engpässe
zu vermeiden hilft. Im Kooperationsprojekt POLE der Universität Hannover (SRA in Zusammenarbeit
mit dem Institut für Verkehrsplanung, Prof. Friedrich) werden lernfähige Steuerungen von Lichtsignalanlagen
mit lokalem Sensorhorizont und ihre Fähigkeit zur Selbstorganisation in großen Verbünden
untersucht. Die Steuerung basiert auf dem im SALSA-Projekt entwickelten lernenden Classifier-
System mit fuzzifizierten Ein- und Ausgangsgrößen. Neben dem lokalen Lernverhalten ist hier
besonders das Verhalten des gesamten Straßennetzes von Interesse. Geklärt werden soll auch die
Stabilität beim Zusammenspiel großer Zahlen von lokalen Steuerungen.
Das Ziel des Projekts Ryyushi ist die Untersuchung adaptiver Stack-Architekturen für den Einsatz in
mobilen Terminals. In Zusammenarbeit mit Siemens entsteht hier ein Protokoll-Baukasten sowie ein
Framework, welches eine dynamische Konfiguration des Stacks erlaubt. Konfigurationsdaten werden
über das Funknetz eingespielt. Forschungsgegenstand ist auch die Definition einer geeigneten Konfigurationssprache.
Besondere Beachtung findet dabei die Sicherheitsproblematik: Konfigurationen
müssen vor der Verteilung validiert und zertifiziert werden. Hierzu kommen Verfahren der Systemsimulation
zum Einsatz.
Eingebettete organische Systeme werden zunehmend sicherheitskritisch. Das SRA arbeitet daher an
Verfahren, welche mittels Zusicherungen (Assertions) die einzuhaltenden Randbedingungen erzwingen
[57,
58,
59,
60].
Die Kombination von Assertions mit einer Systemsimulation erlaubt dabei die
Beobachtung und Überwachung zentraler Systemeigenschaften bereits in der Validierungsphase.
Insbesondere die Erweiterung des Assertionbegriffs von logischen auf Timing-Assertions erlaubt eine
engmaschige Leistungs-Überwachung des eingebetteten Systems.
Die Beschränkung des Emergenzverhaltens organischer eingebetteter Systeme wird ausschlaggebend
für deren technischen Einsatz sein. Im am SRA laufenden Projekt COSY (BMB+F-Förderung
und industrielle Kooperation) werden abstrakte Systembeschreibungen (UML und OCL) mit Constraints
(Assertions nach B. Meyer) instrumentiert, deren Einhaltung sowohl off-line (während der
Simulation) wie auch on-line (im laufenden System) überwacht wird. Verletzungen führen zu Warnungen
oder zu korrigierenden Eingriffen in das System. Constraints werden als wichtige Methode zur
Lernraumbeschränkung von lernenden und selbst-organisierenden Systemen gesehen. Sie dienen als
Schnittstelle zu Überwachungs- und Korrekturkomponenten (Observer).
Die Nutzung von Kontext-Information erlaubt in OC-Systemen die Anpassung an die Umgebung. Der
Austausch von Kontext-Daten und die spontane Peer-to-peer-Vernetzung zwischen mobilen funkvernetzten
Terminals wird im InfoSpaces-Projekt [61,
62] des SRA untersucht. Basis sind Middleware-
Systeme wie Jini, Jxta, UP&P oder Rendezvous. Ein verteilter gemeinsamer Speicher ermöglicht den
Austausch von Information zwischen mobilen Terminals oder mit fest installierten elektronischen
Anschlagtafeln (Infokiosks). Das Informationsangebot der Infokiosks kann damit benutzeradaptiv
gestaltet werden.
Derzeit am SRA beginnende Projekte (in Kooperation mit Siemens, IBM und Daimler Chrysler Research)
beschäftigen sich mit mehrschichtigen Observer-Architekturen, welche eine evolutive und
schrittweise Öffnung und Parametrisierung bestehender Systeme sowie ihre Kontrolle durch höhere
Systemkomponenten zum Ziel haben. Ein weiteres Ziel ist ein grundlegendes theoretisches Verständnis
des Verhaltens komplexer Systeme, seien sie biologisch oder technisch. Hierzu gehören
Metriken zur quantitativen Beurteilung von Selbstorganisations- und Emergenzphänomenen. Weitere
Projekte beschäftigen sich mit Methoden des adaptiven Informations-Clusterings und der Lernfähigkeit
ressourcenbeschränkter adaptiver mobiler Geräte (eingebettetes Lernen).
Ein weiterer wichtiger Anwendungsbereich des Organic Computing liegt im Automotive Sektor, d.h.
bei der Entwicklung von elektronischen Systemen für Kraftfahrzeuge. In den PKWs der großen deutschen
Automobilhersteller wie DaimlerChrysler und BMW übernehmen nämlich bereits seit den 90-er
Jahren eine Vielzahl von verteilten und miteinander in intelligenter Weise kooperierenden eingebetteten
Systemen die Realisierung von Sicherheits- und Komfortfunktion (wie z.B. ABS, ESP, Navigation).
Dieser Trend, mehr und mehr Funktionen mit elektronischen Systemen zu realisieren, wird auch in der
Zukunft unvermindert anhalten. Dabei muss bereits heute bei der Entwicklung und insbesondere der
Integration der elektronischen Komponenten mit einer immensen Komplexität umgegangen werden,
die aber in Zukunft noch weiter anwachsen wird und somit die Stabilität des Gesamtsystems gefährden
könnte. Die Herausforderung für die Fahrzeughersteller liegt deshalb heute vor allem darin,
diesem stetigen Komplexitätszuwachs mit intelligenten Mitteln derart zu begegnen, dass der Entwicklungs-
und Integrationsaufwand dieser Systeme trotzdem minimal ist und eine reibungslose
Funktionalität aller Systeme weiterhin garantiert werden kann.
Da diese Integrationsaufgabe mit passiven Architekturkonzepten, bei denen die einzelnen Komponenten
statisch miteinander verbunden werden, nicht mehr möglich sein wird, müssen aktive Fahrzeugarchitekturen
an deren Stelle treten, die in der Lage sind, sich dynamisch selbst zu organisieren, Fehler
oder Ausfälle im System durch Selbstheilungsprozesse zu beseitigen und sich durch die Fähigkeit der
Selbstadaptierung stets an die aktuellen Anforderungen von Fahrer und Umwelt anzupassen. Dies
setzt eine offene, dynamische Kommunikation von dezentral organisierten und mit einer hohen Autonomie
bzw. Eigenintelligenz ausgestatteten Elektronik-Komponenten voraus, die sich mittels einer Ad-
Hoc-Vernetzung mit anderen Fahrzeugkomponenten, sowie mit Komponenten aus der Umgebung zu
höher organisierten Verbünden zusammenschalten können, um so auch systemübergreifende Aufgaben
bewältigen zu können.
Bei der letzten GI-Jahrestagung war ein Workshop speziell diesem Thema gewidmet (Workshop
"Automotive SW Engineering and Concepts" [63]).
1.2 Wissenschaftliche Ziele
Wie im Abschnitt über den Stand der Wissenschaft erläutert, werden sich die seit Beginn der sechziger
Jahre zu beobachtenden Fortschritte auf dem Gebiet der Rechnerarchitekturen auch in absehbarer
Zukunft mit gleicher Geschwindigkeit fortsetzen. Dies führt unausweichlich selbst im Bereich der
eingebetteten Systeme zu einer nicht mehr beherrschbaren Komplexität, sowohl in Bezug auf den
Entwurfsprozess als auch bezüglich des Einsatzes dieser Systeme.
Das übergeordnete Ziel des geplanten Schwerpunktprogramms ist deshalb die Realisierung neuartiger
Rechner- und Systemarchitekturen, welche der Vision des "Organic Computing" entsprechen. Ein
organischer Computer sei dabei definiert als ein selbstorganisierendes System, das sich den jeweiligen
Umgebungsanforderungen dynamisch anpasst. Organische Informationsverarbeitungsinfrastrukturen
sind folglich selbstkonfigurierend, selbstoptimierend, selbstheilend, selbstschützend und auch
selbsterklärend. Selbstorganisation und Adaptivität mit all ihren Facetten werden nicht nur das System
insgesamt sondern das Verhalten sämtlicher Komponenten eines künftigen Organischen Informationsverarbeitungssystems
bestimmen.
Die Vorteile liegen auf der Hand: Organische Computersysteme verhalten sich eher wie intelligente
Assistenten als wie sture Befehlsempfänger. Sie sind flexibel, robust gegenüber (Teil-)Ausfällen und in
der Lage, sich selbst zu optimieren. Der Entwurfsaufwand sinkt, da nicht jede Variante im Voraus
programmiert werden muss.
Dem stehen jedoch potenziell gravierende Nachteile gegenüber: Lernende Systeme können Fehler
machen, die in technischen, insbesondere sicherheitskritischen Anwendungen aber nicht toleriert
werden können. Lernen bedeutet zunächst unproduktiven Aufwand; dies kann zu langen Trainingsund
Umkonfigurationszeiten, somit zu langen Reaktionszeiten führen. Schließlich eröffnet die Adaptivität
eines Systems auch neue Möglichkeiten für gezielt unerlaubte Beeinflussungen.
Wie in 1.1 beschrieben, ist mit Selbstorganisation auch das Phänomen der Emergenz verbunden.
Dies kann sowohl zu den erhofften Vorteilen der Selbstorganisation beitragen, kann aber auch ein aus
den individuellen Handlungen einzelner Komponenten nicht vorhersehbares Verhalten bewirken, das
auf die aktuelle Umgebung nachteilig wirkt (Dies stünde allerdings im Widerspruch zu der Fähigkeit,
sich stets auf die Bedürfnisse der Umwelt einzustellen.).
Wie man aus der Darstellung des Stands der Wissenschaft sieht, haben sich Soziologen, Informatiker
und Naturwissenschaftler bereits seit längerem mit dem Prinzip der Selbstorganisation und den damit
einhergehenden Phänomenen beschäftigt. Dies führte zu einer Reihe von Ansätzen für eine formale
Modellierung selbstorganisierender Systeme und zu einem größeren Verständnis ihres Verhaltens,
allerdings im Wesentlichen beschränkt auf stark vereinfachte abstrakte Modelle. Bis heute gibt es in
der Informatik relativ wenige Beispiele für konkrete technische Systeme, die die postulierten Eigenschaften
der Selbstorganisation aufweisen - abgesehen beispielsweise von der seit vielen Jahren
sehr erfolgreich operierenden Kommunikationsinfrastruktur des Internets und den Ansätzen für die
Realisierung von adhoc-Netzen mobiler Komponenten.
Das geplante Schwerpunktprogramm soll auf viel versprechende Ansätze aus verschiedenen Teilgebieten
der Rechner- und Systemarchitektur aufbauen, um die Vision der Organischen Rechnersysteme
Realität werden zu lassen. Die wesentlichen Herausforderungen liegen darin, Hardware- und
Software-Systeme zu schaffen, die es erlauben, das Potenzial der Selbstorganisation mit seinen
verschiedenen Facetten auszuschöpfen und dabei gleichzeitig sicherzustellen, dass sich diese Systeme
den menschlichen Bedürfnissen gemäß verhalten.
Trotz vieler interessanter Forschungsansätze sind zentrale Fragen des Organic Computing ungelöst
und bedürfen einer übergreifenden Analyse und Kooperation. Hierzu gehören die folgenden Themen:
- Theorie komplexer Systeme: Ein grundlegendes theoretisches Verständnis des Verhaltens komplexer Systeme, seien sie biologisch oder technisch, fehlt weitgehend. Hierzu gehören auch Metriken zur quantitativen Beurteilung von Selbstorganisations- und Emergenzphänomenen.
-
Zielgerichtete emergente Prozesse: Organic Computing soll über die bisherigen Ansätze hinausgehen, indem nicht die Entwicklung statischer Strukturen studiert wird, sondern die Organisation
zielgerichteter emergenter Prozesse. Die Theorie der Selbstorganisation (z.B. Jetschke in seiner Mathematik der Selbstorganisation) behandelt die Konvergenz einfacher Systeme zu statischen
Formen; die Algorithmik beschäftigt sich mit Verfahren, die aus einem gegebenen Input in akzeptabler Zeit einen gewünschten (statischen) Output berechnen. Was Not tut, ist das Studium
einer Vielzahl von Prozessen, die sich gegenseitig beeinflussen und auf eine ständig variable Umwelt angemessen reagieren. Hierfür ist derzeit keine Theorie in Sicht. Selbst die Modelle der
Wirtschaftstheorie behandeln nicht dynamisch veränderliches Verhalten der Wirtschaftssubjekte, sondern gehen von statischen Verhaltensweisen aus.
-
System-Architekturen: Es ist unrealistisch anzunehmen, dass sich ein komplexes technisches
System (z.B. die 100 Steuergeräte in einem KFZ) spontan und sinnvoll selbst organisiert. Anzustreben
ist vielmehr eine evolutive und schrittweise Öffnung und Parametrisierung bestehender
Systeme sowie ihre Kontrolle durch höhere Systemkomponenten. Hierzu sind unter Anderem
mehrschichtige Controller/Observer-Architekturen zu entwickeln.
-
Eingebettetes Lernen: Die Forderung der Anpassungsfähigkeit eingebetteter Systeme an sich
dynamisch verändernde Anforderungen der Einsatzumgebung kann nur durch lernende Systeme
erfüllt werden. Lernalgorithmen sind jedoch im Allgemeinen zeitaufwendig und/oder benötigen beträchtliche
Rechenressourcen. Diese stehen in eingebetteten hochgradig verteilten Systemen aber
in der Regel nicht ausreichend zur Verfügung, d.h. es sind Vorgehensweisen zu entwickeln,
die beispielsweise Lernen bei beschränkten Ressourcen ermöglichen oder über geeignete Vernetzung
Teilaufgaben an externe Ressourcen auslagern.
-
Lerneffizienz und A-priori-Wissen: Während das Lernverhalten "ab initio" wissenschaftlich
interessant ist, muss in technischen Anwendungen auf Effizienz geachtet werden. Daher ist eine
Verwendung von A-priori-Wissen in Form von vom Entwickler vorgegebenen Regeln vorteilhaft,
damit das Lernverfahren schneller konvergiert.
-
Sicherheit und Beschränkung: Lernende und selbstorganisierende Systeme besitzen per definitionem
die Möglichkeit zur Weiterentwicklung in vom Entwickler nicht explizit vorgeplante Richtungen.
Bei ihrem Einsatz in technischen, häufig sicherheitskritischen Systemen müssen Fehlentwicklungen
verhindert werden, d.h. es sind die gegenläufigen Forderungen nach vielen Freiheitsgraden
zur Ermöglichung von Selbstorganisation und nach ausreichender Kontrolle zur Verhinderung
von Fehlentwicklungen (laterale Beschränkung) gegeneinander auszugleichen. Beispielsweise
darf der (kreative) Versuch einer lernenden Ampelsteuerung, alle 4 Ampeln auf Grün zu schalten,
nicht umgesetzt werden!
-
Selbsterklärung: Ein für ein selbstorganisierendes System verantwortlicher Entwickler muss
Einblick und Kontrollmöglichkeiten behalten. Die Systeme sollten daher selbst-erklärend sein (eine
Eigenschaft, die beispielsweise ein Künstliches Neuronales Netz nicht hat).
-
Hardware-Basis: Der organische Computer benötigt neue Chip-Generationen, die sich durch
dynamische Rekonfigurierbarkeit, Adaptivität, Robustheit und hohe Fehlertoleranz auszeichnen.
Diese werden nach wie vor elektronisch realisiert sein, da darüber hinausgehende hybride Formen
der Informationsverarbeitung oder auch DNA-Computing oder Quanten-Computing bis 2010
noch keine Rolle spielen werden. Stattdessen wird eine Nanotechnik für Aufbau und Verbindung
benötigt, die mehr als heute die Integration räumlicher Strukturen erlaubt. Ein Übergang von planaren
zu 3-D Strukturen ist erforderlich, um die in der Mikroelektronik immer problematischer werdende
Verdrahtungskrise zu lösen. Da auch die Hochintegration weiter voranschreiten wird, können
dann vollständige Systeme auf kleinstem Raum realisiert werden. Zusammen mit geeignet zu
entwickelnden Architekturen kann eine Aufweichung des für den organischen Computer zu starren
traditionellen von-Neumann-Architektur-Konzeptes erfolgen. Speicher und Prozessoren können
sich ebenso vermischen wie On-chip-Parallelprozessoren mit rekonfigurierbaren Architekturen.
Ebenso besteht Forschungsbedarf an verbesserten Mixed-Signal-Schaltkreisen, um analoge Signalerfassung
mit paralleler digitaler Signalverarbeitung auf engstem Raum zu koppeln. Dies bildet
die Voraussetzung für den Einsatz intelligenter Sensor-Chips in biologisch inspirierten Rechnern
und in autonomen Robotern.
Ein Workshop zum Organic Computing am 1./2.12.2003 in Hannover hatte mit 40 Teilnehmern und 25
Einzelvorträgen über ein breites Themenspektrum eine beachtliche Resonanz bei bemerkenswert
hoher Industriebeteiligung. In dem geplanten Schwerpunktprogramm werden deshalb zahlreiche
Forschungsanträge zu allen oben angesprochenen Fragestellungen erwartet. Die Ziele dieser Forschungsaktivitäten
sollen sich dabei schwerpunktmäßig in die folgenden drei Themenbereiche gliedern
-
Beherrschung der Selbstorganisation in technischen Systemen
Es ist nicht die Frage, ob adaptive und selbstorganisierende Systeme entstehen sondern wie wir
sie gestalten. Dem Albtraum eines autonomen Systems, das seinen eigenen "Willen" durchsetzt,
steht die Vision von freundlichen Systemen gegenüber, welche nicht bedient werden sondern die
den Menschen bedienen. Bereits jetzt ist die Komplexität der uns umgebenden vernetzten informationsverarbeitenden
Systeme zu groß, um noch eine effektive globale Steuerung vornehmen
zu können. Grundlegende Erkenntnisse über das Verhalten komplexer Systeme sollen Wege aufzeigen,
wie technischen Systemen durch geeignete Verhaltensregeln die notwendigen Freiheitsgrade
für selbstorganisierendes Handeln eröffnet werden können und in welchem Maße und mit
welchen Mitteln gleichzeitig Beschränkungen auferlegt werden können, die ein fehlentwickeltes
eigenständiges Handeln verhindern. Diesem Themenschwerpunkt werden deshalb Aktivitäten zugerechnet,
die sich mit der Theorie komplexer Systeme, mit zielgerichteten Prozessen und mit Sicherheit
und lateraler Beschränkung befassen. Ein wesentliches Thema dieser Aktivitäten wird
dabei die Frage betreffen, unter welchen Bedingungen bei selbstorganisierenden technischen
Systemen emergentes Verhalten auftreten kann, d.h. es muss einerseits darum gehen, bewusst
gewünschtes emergentes Verhalten zu erzeugen, während gleichzeitig Methoden bereitgestellt
werden müssen, um das Auftreten unerwünschter Emergenz rechtzeitig zu erkennen und zu vermeiden.
Dies wird vermutlich die Entwicklung mehrschichtiger Controller-Observer-Strukturen erfordern.
Ein weiterer wichtiger Punkt dieses Bereiches sind Methoden der Validierung, ob vorgegebene
technische Systeme postulierte Beschränkungen ihrer Handlungsfähigkeit einhalten (auch dies
hat mit Emergenz zu tun). Dies setzt ein hohes Maß an Transparenz voraus, die unter Anderem
durch selbsterklärendes Verhalten erzielt werden soll.
Schließlich gehört zum Ziel der Beherrschung der Selbstorganisation technischer Systeme auch
die Beachtung von Rechtsfragen: Beispielsweise müssen Haftungsfragen geklärt werden, da es
keineswegs offensichtlich ist, wer für die Wirkungen des Handelns selbstorganisierender Systeme
haftbar gemacht werden kann. Ohne eine befriedigende Lösung dieser Aspekte der Beherrschung
selbstorganisierender technischer Systeme dürfte es zu recht schwierig sein, eine ausreichende
gesellschaftliche Akzeptanz für diese Systeme zu erzielen.
-
Technologien für Organic Computing
Schwerpunkt des Programms wird die technische Nutzung der Prinzipien der Selbstorganisation
und der Adaptivität sein. Dies erfordert zum einen die Entwicklung von Basistechnologien, die
die Grundlagen für eine Realisierung organischer Rechensysteme liefern, dazu zählt die oben erwähnte
Hardware-Basis. Zum anderen sind Konzepte für den Entwurf, die Gestaltung und den Betrieb
von esamtsystemen zu entwickeln. Insofern sind die hier zusammengefassten Forschungsaktivitäten
noch einmal in zwei, allerdings eng verbundene Bereiche gegliedert.
OC-Basistechnologien bilden die Grundlage für den Aufbau selbstorganisierender Gesamtsysteme
und lassen sich in unterschiedlichen Zusammenhängen einsetzen. Im weitesten Sinn lassen
sich die Basistechnologien als Werkzeugkasten für die weitere Verwendung im Anwendungsbereich
verstehen.
Zu den Basistechnologien zählen
- Anwendung von Artificial-Life-Konzepten undanderer naturanaloger Prinzipien (Schwarmintelligenz etc.) auf technische Systeme
- Kommunikations- und Rechenprinzipien für selbstorganisierende Systeme (also insbesondere der gezielte Einsatz rekonfigurierbarer Rechensysteme)
- Nutzung von Lokalität und Kontext
- Effizientes Lernen in hochgradig verteilten Systemen mit beschränkten Ressourcen; Nutzung von a-priori-Wissen
- Erhöhung der Energieeffizienz mobiler, eingebetteter Systeme
- Nutzerschnittstellen und Interaktionsmedien für organische Rechensysteme (taktil, mental, ...)
- Verfahren für flexible Taskverteilung und Ad-hoc-Kommunikation sowie zur selbstorganisierten Verteilung von Aufgaben in organischen Rechensystemen
Für den Entwurf und die Gestaltung von Gesamtsystemen sind geeignete (mehrstufige) Systemarchitekturen
zu entwickeln, hier wird die übergeordnete Schicht im Sinne der Selbstorganisation
als Observer bezüglich der unteren Schicht dienen. Außerdem werden Analysemethoden und
Metriken zur Beurteilung der Effektivität und der Effizienz selbstorganisierender Systeme benötigt.
Für organische Systeme auf einem Chip lassen sich die angestrebten Eigenschaften auch wie
folgt charakterisieren:
Bei zunehmendem Arbeitsaufkommen werden Taktfrequenz und Versorgungsspannung einzelner
Prozessorkerne erhöht und somit ihre Verarbeitungsleistung gesteigert. Gleichzeitig wird die Priorität
von kritischen Transaktionen auf Verbindungsbussen, z.B. zwischen Prozessoren und Systemspeicher,
angehoben und die Busbandbreite niederpriorer Verbindungen reduziert. Redundante,
im Normalbetrieb deaktivierte Funktionsbausteine werden zur Leistungsanhebung zugeschaltet.
Im Gegenzug werden sekundäre Systemfunktionen zwecks Reduzierung der Verlustleistung
temporär stillgelegt. Monitoring- und Selbsttesteinheiten veranlassen bei auffälligem Verhalten
einzelner Funktionsblöcke oder Schnittstellen das Schreiben von Diagnose-Traces in bestimmte
Speicherbereiche und/oder sie werden in Echtzeit durch Analyseeinheiten ausgewertet. Das Resultat
dieser Analyse wird entweder externen Kontrolleinheiten zur Verfügung gestellt, und/oder
dient zur Zu- oder Abschaltung einzelner Blöcke.
Um auf höherer (Gesamt-)Systemebene eine ähnliche Funktionalität gewährleisten zu können,
müssen die unter Stand der Wissenschaft bereits erwähnten organischen ubiquitären Middleware-
Konzepte noch deutlich erweitert werden.
-
Anwendungsgetriebene OC-Forschung
Wie bereits mehrfach betont wurde, kommen starke Anstöße für das Konzept des Organic Computing
aus verschiedenen Initiativen der Industrie, mit denen auf bereits vorliegende oder absehbare
Probleme in komplexen Anwendungssystemen reagiert wurde (beispielsweise im Automobilbereich
oder bei unternehmensweiten Serverarchitekturen). Im Rahmen des SPP sollen zwar keine
expliziten Anwendungen entwickelt werden. Es erscheint jedoch unabdingbar, die Vorhaben
aus dem Bereich der OC-Technologie an potenziellen technischen Anwendungsgebieten zu spiegeln.
Gefördert werden sollen hier also nur solche Vorhaben, die aus einem konkreten Anwendungsbezug
heraus grundlegende und allgemeiner einsetzbare Verfahren und Basistechnologien
entwickeln. In diesem Bereich sehen wir auch Konzepte zur Realisierung von Systemen, die ihre
Dienste bei Bedarf bereit stellen (umgebungsangepasst), aber ansonsten "unsichtbar" sind (the
"disappearing computer", "calm computing", siehe Abschnitt 2.3).
Insbesondere sollen hier die Anwendungsbereiche Automobiltechnik, Telekommunikation und
Prozessautomatisierung berücksichtigt werden, in letzterem wäre das Ziel die "smart factory"
Ein weiterer Anwendungsbereich mit steigender Bedeutung für zukünftige organische Systeme ist
die "Anthropomatik", ein interdisziplinäres Forschungsgebiet, das den Einsatz von Informatik und
Technik stark auf die ganz speziellen individuellen Bedürfnisse des einzelnen Menschen abstimmt,
etwa zum Ausgleich individueller Leistungseinbußen, wie sie zum Beispiel krankheits- oder
altersbedingt auftreten können. Der Organische Computer mit seinen per se lebensähnlichen
Eigenschaften soll als Basis zur Realisierung solcher Anwendungen dienen. Zum Einsatz kommen
werden hier in starkem Maße Geräte des "wearable computing".
1.3 Arbeitsprogramm
Das Schwerpunktprogramm ist auf einen sechsjährigen Zeitraum ausgelegt. Dabei wird davon ausgegangen,
dass in der ersten Antragsrunde eine zunächst zweijährige Laufzeit der Projekte vorgesehen
ist. Damit ist mit drei Phasen des Schwerpunktprogramms zu rechnen.
Wir sehen Forschungsbedarf in den drei Arbeitsbereichen (1) Prinzipien der Selbstorganisation, (2)
Technologien für Organic Computing und (3) Anwendungsgetriebene OC-Forschung, wobei ein Rückbezug
auf natürliche Phänomene immer die Basis bilden sollte. Abb.1 zeigt die Abhängigkeiten, nicht
jedoch den zeitlichen Ablauf des des Gesamtprojekts, Abb. 2 zeigt die näherungsweise beabsichtigte
Aufwandsverteilung während der drei Phasen.
In Phase 1 soll die Betonung auf dem grundlegenden Verständnis der Prinzipien der Selbstorganisation
und der Realisierung einer technischen Nutzung liegen. Wir erwarten in Phase 1 den Großteil der
grundlegenden Arbeiten zu OC-Prinzipien. In Phase 2 soll sich das Gewicht deutlich in Richtung auf
die technische Nutzung verlagern. Dies wird auch in der dritten Phase so bleiben. Hier sehen wir
allerdings eine leichte Verschiebung hin zu mehr anwendungsbezogenen Aspekten. Es scheint den
Antragstellern wesentlich, dass während der gesamten Laufzeit des Schwerpunktprogramms alle drei
Arbeitsbereiche verfolgt werden, wenn auch mit unterschiedlicher Gewichtung.
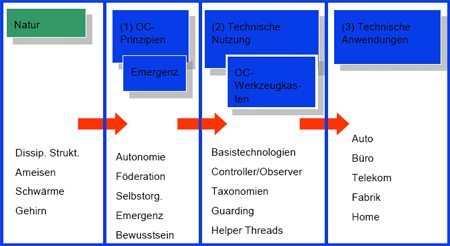
Abb. 1: Struktur des Schwerpunktprogramms Organic Computing mit den 3 Arbeitsbereichen. Dieses
Bild stellt nicht den zeitlichen Ablauf des Projekts dar.
Abb. 2: Näherungsweise Verteilung der Aufwände in den 3 Phasen des Schwerpunktprogramms auf
die 3 Arbeitsbereiche
1.3.1 Prinzipien der Selbstorganisation
Basis aller Arbeiten muss ein tief greifendes und vor allem auch quantitatives Verständnis der Prinzipien
der Selbstorganisationsprozesse sein. Diese Prinzipien lassen sich an natürlichen Systemen
(dissipative Strukturen, Staaten bildende Insekten, Gehirn), aber auch an künstlichen Systemen
(Gitterwelten) studieren. Dabei sollen insbesondere das Auftreten, die Erzeugung und die Kontrolle
emergenten Verhaltens untersucht werden. Gefördert werden sollen hier aber nur Vorhaben mit direkt
sichtbarem Bezug zur technischen Nutzung.
1.3.2 Technologien für Organic Computing
Das Ziel der Bereitstellung eines "Werkzeugkastens" für die Konstruktion organischer Systeme wird
vermutlich über einen evolutiven Prozess erreichbar sein. Die Grundannahme ist, dass die technischen
Komponenten, die in 6 bis 10 Jahren im Organic Computing zum Einsatz kommen, nicht unbedingt
prinzipiell von heute bereits verfügbaren Komponenten verschieden sein müssen. Angestrebt
wird eine schrittweise Erweiterung bestehender technischer Komponenten und Architekturen. So
müssen rekonfigurierbare Rechensysteme um die unterschiedlichen Aspekte der Selbstorganisation
erweitert werden, Adaptivität über geeignete Parametrisierungen dürfte durch dynamische Rekonfiguration
erreichbar sein. Das Konzept des System-on-Chip (SoC) erlaubt beispielsweise die anwendungsspezifische
Realisierung komplexer Systeme aus unterschiedlichen Komponenten.
Aufgrund der Forschungsinitiativen des Autonomic Computing und der Organic IT Ansätze sind einige
neue Forschungsansätze angestoßen werden, die im Rahmen dieses Schwerpunktprogramms weiterentwickelt
und ausgebaut werden könnten. Allerdings soll es bei den technischen Systemen nicht
um die vom Organic-IT adressierten unternehmensweiten Serverarchitekturen gehen, ebenso ist das
von IBM im Autonomic Computing angesprochene verbesserte Management großer Systeme unter
Verwendung von Merkmalen der Selbstorganisation nicht im Fokus des Schwerpunktprogramms.
Neben Vorhaben, welche die Parametrisierung und (Selbst-)Adaption von Hardware- und Software-
Komponenten zum Ziel haben, sind hier vor allem neuartige Gesamt-Systemarchitekturen zu entwickeln.
Hierzu zählen Mechanismen zur Kooperation zwischen Einzelkomponenten, welche zunächst
noch stark vom Entwickler vorbestimmt sein werden, in Zukunft jedoch zunehmend selbständig agieren
sollen. Wichtig ist von Beginn an die Berücksichtigung von Sicherheitskonzepten. Es ist zu erwarten,
dass sich heutige Middleware-Architekturen wie Jini, Jxta oder UP&P zu einer selbstorganiserenden
Systemschicht weiter entwickeln werden.
1.3.3 Anwendungsgetriebene OC-Forschung
Die Bedeutung dieses dritten Arbeitspakets wird im Verlauf des Schwerpunktprogramms wachsen.
Während es zunächst eher um Bestandsaufnahmen und Anforderungsanalysen für Organic Computing
Anwendungen gehen wird, dürften erst in den späteren Phasen des Schwerpunktprogramms die
notwendigen Erkenntnisse gewonnen und geeignete Werkzeuge entwickelt werden, um konkrete
Anwendungsfälle des Organic Computing realisieren zu können. In diesem Bereich werden in besonderem
Maße auch Forschungsbeiträge von industriellen Partnern erwartet, die bereits im Vorfeld
starkes Interesse an diesem Schwerpunktprogramm geäußert haben (wie die Unternehmen DaimlerChrysler,
IBM und Siemens).
1.3.4 Richtlinien für Antragsteller
Im Rahmen dieses Schwerpunktprogramms sollen Projekte gefördert werden, die Beiträge zu den in
diesem Antrag genannten Themenbereichen liefern. Gegenstand des Interesses sind also in der
ersten Phase vor allem Untersuchungen zum grundlegenden Verständnis der Prinzipien der Selbstorganisation
und zur Entwicklung einer technologischen Basis von Systemen des Organic Computing
Idealerweise sollte der Schwerpunkt eines beantragten Projekts auf einem dieser Teilziele liegen,
jedoch stets um aussichtsreiche Teilaspekte des jeweils anderen Bereichs ergänzt werden. Aspekte
der Selbstorganisation sollten im Projektantrag klar erkennbar sein. Nicht gefördert werden sollen
Projekte zu den Themenkomplexen besonderer Rechnerparadigmen wie DNA- und Quantencomputing,
optische Rechner sowie Projekte im Bereich der Softwaremethodenentwicklung, die den Aspekt
der Selbstorganisation nicht direkt zum Gegenstand haben. Im Bereich der anwendungsgetriebenen
OC-Forschung sollen hier also nur solche Vorhaben gefördert werden, die aus einem Anwendungsbezug
heraus grundlegende und allgemeiner einsetzbare Verfahren und Basistechnologien entwickeln.
Alle Projekte sollten zunächst für eine zweijährige Laufzeit beantragt werden, sie sollten aber eine
deutlich längere Perspektive haben.
|
|
|
